



Business Intelligence Oefeningen: Praktijkvoorbeelden & Templates
De snelste manier om BI te leren is niet erover lezen — het is doen. Hier zijn 10 business intelligence oefeningen die echte bedrijfsscenario’s weerspiegelen, compleet met voorbeelddata en stapsgewijze instructies.
Business intelligence oefeningen zijn gestructureerde, scenariogebaseerde praktijkproblemen die analisten, managers en consultants trainen om ruwe data om te zetten in beslissingen. Ze omvatten het aanmaken van dashboards, KPI-analyse, segmentatie, forecasting en strategische simulatie. Werk ze in volgorde door en u bouwt een complete, boardklare BI-vaardighedenset op — van uw eerste verkoopgrafiek tot een volledige BI-strategiesimulatie.
Inhoudsopgave
- Wat zijn business intelligence oefeningen?
- 10 praktische BI-oefeningen met voorbeelddata
- Hoe structureert u uw BI-leerpad?
- Het Scenario-to-Signal-framework
- Belangrijkste inzichten
- Veelgestelde vragen
Wat zijn business intelligence oefeningen?
Business intelligence oefeningen zijn scenariogebaseerde praktijkproblemen die de vaardigheden opbouwen die nodig zijn om data te verzamelen, te modelleren, te analyseren en te presenteren voor echte zakelijke beslissingen. Ze variëren van het bouwen van een eenvoudig verkoopdashboard in Excel tot het simuleren van een volledige BI-strategie voor een bedrijf van €50 miljoen. Regelmatig geoefend, overbruggen ze de kloof tussen het kennen van BI-theorie en het daadwerkelijk leveren van inzichten waarop directies actie ondernemen.
Definitie & doel
De meeste BI-cursussen leren tools. Oefeningen leren oordeelsvermogen. Het verschil is belangrijk omdat tools veranderen — Power BI, Tableau, Qlik, Looker — maar het onderliggende analytische redeneren constant blijft. Een goed ontworpen oefening dwingt u de vraag te stellen: Welke beslissing moet deze data mogelijk maken? Die vraag is de basis van elke effectieve BI-deliverable.
Het doel is niet het produceren van mooie grafieken. Het doel is het produceren van beslissingen.
Wie heeft BI-praktijkoefeningen nodig?
Vier verschillende doelgroepen profiteren van gestructureerde BI-praktijk:
- Analisten die technische diepgang opbouwen in SQL, DAX of Python
- Managers die dashboards moeten kunnen lezen en bevragen, niet alleen consumeren
- Studenten die zich voorbereiden op BI-analistfuncties en sollicitatiebeoordelingen
- Consultants die clientscenario’s in gecontroleerde omgevingen moeten kunnen repliceren voordat ze live gaan
De oefeningen in deze gids zijn primair geschreven voor analisten en consultants bij Benelux-kmo’s — bedrijven tussen €5 miljoen en €100 miljoen omzet, waar één persoon vaak drie analytische rollen tegelijk vervult.
Soorten BI-oefeningen
Drie categorieën bestrijken het volledige spectrum:
- Analytische oefeningen — segmentatie, forecasting, KPI-analyse, anomaliedetectie
- Technische oefeningen — SQL-queries, datamodellering, ETL-transformatie, DAX-measures
- Strategische oefeningen — BI-roadmapontwerp, governance-frameworks, boardrapportagesimulatie
De 10 onderstaande oefeningen zijn gesequenceerd om alle drie de vaardigheidstypen progressief op te bouwen.
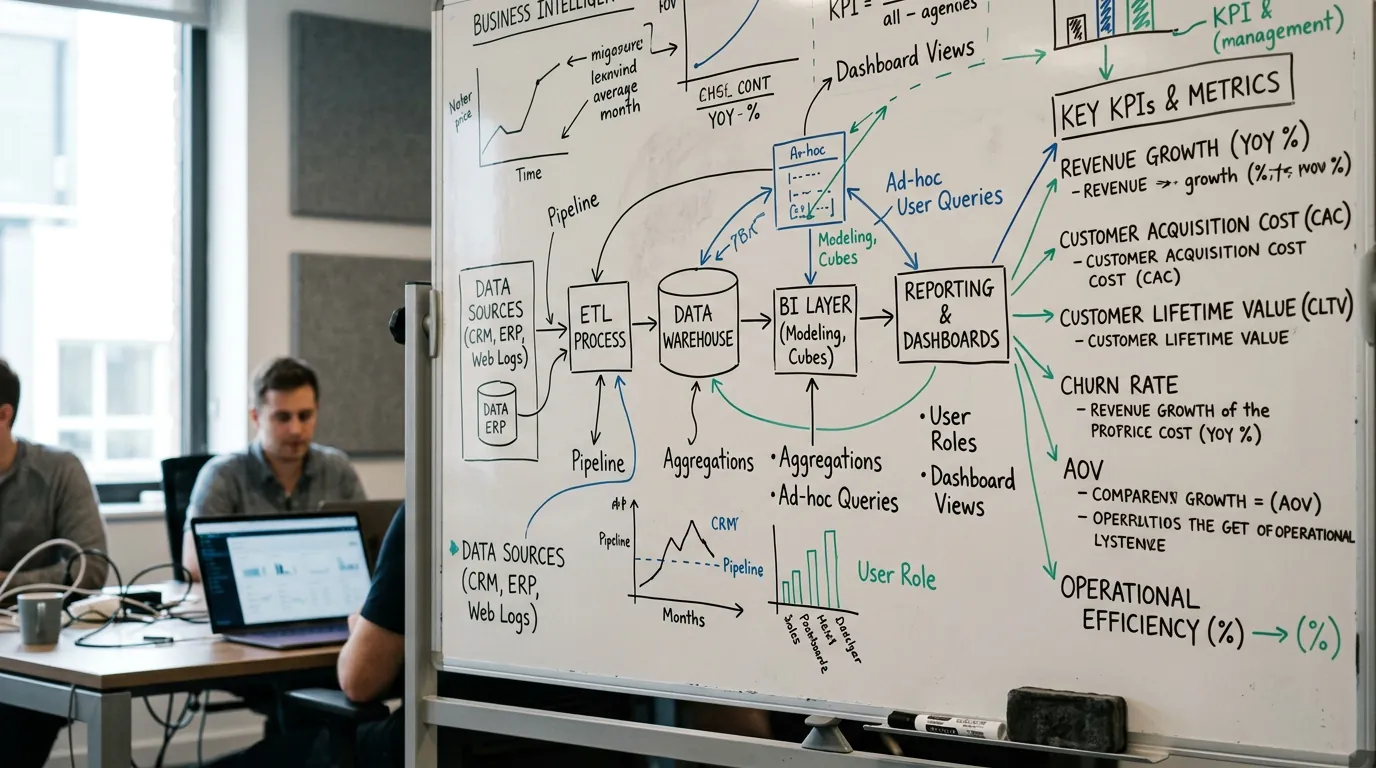
10 praktische BI-oefeningen met voorbeelddata
Deze 10 oefeningen gaan van beginner tot expert en behandelen de kernvaardigheden die elke BI-beoefenaar nodig heeft: dashboardontwerp, KPI-definitie, segmentatie, forecasting, supply chain-tracking, financiële automatisering, marktmandeanalyse, churnvoorspelling, realtime monitoring en volledige strategiesimulatie. Elke oefening volgt dezelfde structuur: Scenario → Dataset → Stappen → Verwachte output → Uitdaging voor gevorderden.
Gebruik deze vergelijkingstabel om uw startpunt te bepalen:
| # | Oefening | Moeilijkheidsgraad | Primaire tool | Tijdschatting | Kernvaardigheid |
|---|---|---|---|---|---|
| 1 | Aanmaken van een verkoopdashboard | Beginner | Power BI / Excel | 2–3 uur | Dashboardontwerp |
| 2 | KPI-analyse & anomaliedetectie | Beginner | Excel / SQL | 2–3 uur | KPI-definitie |
| 3 | Klantsegmentatie (RFM) | Gemiddeld | SQL / Python | 3–4 uur | Segmentatie |
| 4 | Omzetforecastingmodel | Gemiddeld | Excel / Python | 4–5 uur | Forecasting |
| 5 | Supply chain-prestatietracking | Gemiddeld | Power BI / SQL | 3–4 uur | Operationele analyse |
| 6 | Automatisering van financiële rapportage | Gevorderd | SQL / Power BI | 5–6 uur | Finance BI |
| 7 | Marktmandeanalyse | Gevorderd | Python / SQL | 4–5 uur | Associatieregels |
| 8 | Churnvoorspellingsdashboard | Gevorderd | Python / Power BI | 5–6 uur | Predictieve BI |
| 9 | Realtime monitoringopzet | Expert | SQL / streaming | 6–8 uur | Live data |
| 10 | Volledige BI-strategiesimulatie | Expert | Alle tools | 8–10 uur | Strategische BI |
Oefening 1 — Aanmaken van een verkoopdashboard (Beginner)
Scenario: U bent junior analist bij een in Rotterdam gevestigde groothandelsdistributeur met 12 vertegenwoordigers. De verkoopdirecteur wil een eenpagina-dashboard met maandelijkse omzet, de top 10 klanten op waarde en regionale prestaties. U beschikt over een platte CSV-export uit het ERP.
Dataset: Gebruik Microsoft’s AdventureWorks-voorbeelddata of maak een CSV aan met kolommen: OrderDate, CustomerName, Region, ProductCategory, Revenue, Units.
Stappen:
1. Laad uw CSV in Power BI Desktop (of Excel Power Query).
2. Maak een berekende kolom Month-Year aan: FORMAT([OrderDate], "MMM YYYY").
3. Bouw een lijndiagram: Month-Year op de X-as, som van Revenue op de Y-as.
4. Voeg een staafdiagram toe: Top 10 CustomerName op Revenue (gebruik het Top N-filter in de visual).
5. Voeg een kaart- of matrixvisual toe: Region versus Revenue.
6. Voeg drie KPI-kaarten toe: Total Revenue, Total Units, Average Order Value.
7. Pas een datumslicer toe zodat de verkoopdirecteur op kwartaal kan filteren.
Verwachte output: Een eenpagina-dashboard waarbij het klikken op een regio alle andere visuals filtert. Omzettrend in één oogopslag zichtbaar. Top-klanten gerangschikt zonder handmatig sorteren.
Uitdaging voor gevorderden: Voeg een doellijn toe aan de omzettrend (bijv. 5% boven dezelfde maand van het vorige jaar) en kleurcode maanden die de doelstelling misten in rood.
Pro Tip: Gebruik in Power BI de visual “Decomposition Tree” om de verkoopdirecteur te laten inzoomen op de reden waarom een regio ondermaats presteerde — zonder dat u voor elke vraag een apart rapport hoeft te bouwen.
Oefening 2 — KPI-analyse & anomaliedetectie (Beginner)
Scenario: Een in Utrecht gevestigd SaaS-bedrijf volgt maandelijks vijf KPI’s: MRR, churnpercentage, CAC, LTV en NPS. De CFO merkte op dat de omzet er vlak uitzag ondanks groei in nieuwe klanten. Uw taak: vind de anomalie.
Dataset: Bouw een eenvoudige Excel-tabel met 12 maanden aan data. Voeg één bewuste anomalie in — bijvoorbeeld een maand waarin de CAC verdubbelde maar het aantal nieuwe klanten gelijk bleef (wat wijst op een verschuiving in de kanaalsamenstelling).
Stappen:
1. Bereken in Excel de maand-op-maand procentuele verandering voor elke KPI: =(B2-B1)/B1.
2. Pas voorwaardelijke opmaak toe: rood voor negatieve MoM-verandering, groen voor positief.
3. Maak een combinatiediagram: MRR als staaf, churnpercentage als lijn op de secundaire as.
4. Voeg een “vlag”-kolom toe: =IF(ABS(MoM_Change)>0.15,"ANOMALY","OK").
5. Bouw een draaitabel die gemarkeerde maanden per KPI samenvat.
Verwachte output: Een gemarkeerde lijst van maanden waarin een KPI meer dan 15% MoM bewoog. De CFO ziet onmiddellijk dat maand 7 een CAC-piek had — en het gesprek verschuift van “omzet ziet er vlak uit” naar “onze betaalde zoekkosten zijn verdubbeld.”
Uitdaging voor gevorderden: Schrijf een SQL-versie van de anomalievlag met een vensterfunctie:
SELECT
month,
kpi_name,
value,
LAG(value) OVER (PARTITION BY kpi_name ORDER BY month) AS prev_value,
ROUND((value - LAG(value) OVER (PARTITION BY kpi_name ORDER BY month))
/ NULLIF(LAG(value) OVER (PARTITION BY kpi_name ORDER BY month), 0) * 100, 1)
AS mom_change_pct,
CASE
WHEN ABS((value - LAG(value) OVER (PARTITION BY kpi_name ORDER BY month))
/ NULLIF(LAG(value) OVER (PARTITION BY kpi_name ORDER BY month), 0)) > 0.15
THEN 'ANOMALY'
ELSE 'OK'
END AS flag
FROM kpi_monthly
ORDER BY month, kpi_name;
Oefening 3 — Klantsegmentatie met RFM (Gemiddeld)
Scenario: Een in Antwerpen gevestigde e-commerceretailer heeft 8.000 klanten en een vast marketingbudget. Ze willen stoppen met het sturen van dezelfde nieuwsbrief naar iedereen en beginnen met het targeten van hoogwaardige segmenten. U bouwt een RFM-model — Recency, Frequency, Monetary.
Dataset: Download de Online Retail-dataset van de UCI Machine Learning Repository — 541.909 transacties, vrij beschikbaar.
Stappen:
1. Bereken in SQL of Python drie metrics per klant:
– Recency: Dagen sinds de laatste aankoop (relatief aan de maximale datum in de dataset)
– Frequency: Aantal afzonderlijke orders
– Monetary: Totale besteding
SELECT
CustomerID,
DATEDIFF(day, MAX(InvoiceDate), '2011-12-10') AS recency,
COUNT(DISTINCT InvoiceNo) AS frequency,
ROUND(SUM(Quantity * UnitPrice), 2) AS monetary
FROM retail_transactions
WHERE CustomerID IS NOT NULL
GROUP BY CustomerID;
- Scoor elke metric van 1–5 met
NTILE(5)(5 = beste). Let op: voor Recency geldt dat minder dagen beter is, dus keer de scoring om. - Concateneer scores tot een RFM-cel:
R_score || F_score || M_score(bijv. “555” = kampioen). - Wijs cellen toe aan segmenten: Kampioenen (555, 554), Loyaal (444–544), At Risk (211–311), Verloren (111–211).
- Visualiseer segmentgroottes en gemiddelde monetaire waarde in Power BI of een Python-staafdiagram.
Verwachte output: Een gesegmenteerde klanttabel. Kampioenen (doorgaans 5–10% van de klanten) genereren 30–40% van de omzet. At-Risk-klanten zijn kandidaten voor een win-back-campagne.
Uitdaging voor gevorderden: Bereken de omzet die verloren gaat als uw At-Risk-segment volledig churnt. Presenteer dit als één enkel getal aan de marketingdirecteur — dat is de budgetrechtvaardiging voor een retentiecampagne.
Bron: UCI Online Retail Dataset, illustratieve segmentatie
Oefening 4 — Omzetforecastingmodel (Gemiddeld)
Scenario: De CFO van een Gents productiebedrijf (€28 miljoen jaaromzet) heeft een 12-maandenomzetforecast nodig voor de boardpresentatie. Historische maandelijkse omzet is beschikbaar voor 36 maanden.
Dataset: Genereer 36 maanden aan synthetische omzetdata met een trendcomponent (+2% MoM gemiddeld) en seizoensgebondenheid (Q4-pieken 20% boven de basislijn).
Stappen:
1. Zet de historische omzet in Excel uit als lijndiagram.
2. Pas een voortschrijdend gemiddelde van 3 maanden toe om ruis te egaliseren: =AVERAGE(B2:B4).
3. Gebruik de Excel-functie FORECAST.ETS voor exponentiële afvlakking met seizoensgebondenheid:
=FORECAST.ETS(target_date, values, timeline, seasonality=12).
4. Bouw een betrouwbaarheidsinterval: =FORECAST.ETS.CONFINT(target_date, values, timeline, 0.95).
5. Repliceer in Python (optioneel) met statsmodels:
from statsmodels.tsa.holtwinters import ExponentialSmoothing
import pandas as pd
model = ExponentialSmoothing(
revenue_series,
trend='add',
seasonal='add',
seasonal_periods=12
).fit()
forecast = model.forecast(12)
print(forecast)
- Presenteer drie scenario’s: Basis (ETS), Optimistisch (+10%), Conservatief (-10%).
Verwachte output: Een 12-maandenforecasttabel met betrouwbaarheidsbanden. Het board ziet een bandbreedte, niet één enkel getal — wat eerlijker en beter verdedigbaar is.
Uitdaging voor gevorderden: Voeg een “what-if”-schuifregelaar toe in Excel (via een datatabel) die de groeiveronderstelling aanpast van -5% tot +15% en het 12-maandentotaal automatisch herberekent.
Oefening 5 — Supply chain-prestatietracking (Gemiddeld)
Scenario: Een logistiek bedrijf met 200 medewerkers in Breda volgt 15 KPI’s over drie magazijnen. De operationeel directeur wil één dashboard met het percentage tijdige leveringen, de vulgraad en de voorraadrotatie — dagelijks bijgewerkt vanuit een SQL-database.
Dataset: Gebruik de Northwind-database — vrij beschikbaar, inclusief orders, verzendingen, producten en leveranciers.
Stappen:
1. Schrijf SQL-queries voor elke KPI:
-- Percentage tijdige leveringen
SELECT
YEAR(ShippedDate) AS yr,
MONTH(ShippedDate) AS mo,
COUNT(*) AS total_orders,
SUM(CASE WHEN ShippedDate <= RequiredDate THEN 1 ELSE 0 END) AS on_time,
ROUND(100.0 * SUM(CASE WHEN ShippedDate <= RequiredDate THEN 1 ELSE 0 END)
/ COUNT(*), 1) AS otd_rate_pct
FROM Orders
WHERE ShippedDate IS NOT NULL
GROUP BY YEAR(ShippedDate), MONTH(ShippedDate);
- Verbind Power BI rechtstreeks met uw SQL-database (DirectQuery-modus voor “live” verversing).
- Bouw een stoplichtmatrix: elk magazijn × elke KPI, gekleurd op drempelwaarde (groen/oranje/rood).
- Voeg een trendsparkline toe voor elke KPI via de ingebouwde sparkline-functie van Power BI.
- Stel een dagelijkse geplande verversing in via Power BI Service.
Verwachte output: De operationeel directeur opent elke ochtend één URL en ziet welk magazijn aandacht nodig heeft — zonder iemand om een rapport te hoeven vragen.
Voor meer context over hoe supply chain-BI past in een bredere operationele strategie behandelt de Supply Chain 4.0-gids de automatiseringslaag die bovenop dit soort tracking ligt.

Oefening 6 — Automatisering van financiële rapportage (Gevorderd)
Scenario: Het financeteam van een in Brussel gevestigd professioneel dienstverlener besteedt elke maand 3 dagen aan het handmatig opbouwen van een winst-en-verliesrapport in Excel. U automatiseert dit met SQL + Power BI, waardoor dit teruggebracht wordt naar 20 minuten.
Dataset: Maak een tabel gl_transactions aan met kolommen: posting_date, account_code, account_name, department, debit, credit, cost_centre.
Stappen:
1. Bouw een SQL-view die de winst en verlies per rekeninggroep berekent:
CREATE VIEW vw_pl_monthly AS
SELECT
FORMAT(posting_date, 'yyyy-MM') AS period,
account_group,
department,
SUM(credit - debit) AS net_amount
FROM gl_transactions
JOIN chart_of_accounts ON gl_transactions.account_code = chart_of_accounts.account_code
GROUP BY FORMAT(posting_date, 'yyyy-MM'), account_group, department;
- Verbind Power BI met deze view.
- Bouw een matrixvisual: rijen = rekeninggroepen (Omzet, COGS, Brutowinst, OpEx, EBITDA), kolommen = maanden.
- Voeg variantiekolommen toe: Werkelijk versus Budget, Werkelijk versus Vorig jaar.
- Voeg een afstemmingscontrole toe: de totale omzet in het BI-rapport moet overeenkomen met het totaal van het grootboeksysteem. Bouw dit als een kaartvisual met een voorwaardelijke melding (rood als de afwijking > €1.000 is).
Verwachte output: Een live winst-en-verliesrapport dat automatisch ververst. Het handmatige proces van 3 dagen van het financeteam wordt een review van 20 minuten.
Uitdaging voor gevorderden: Voeg een drill-through-pagina per afdeling toe zodat de CFO op elke kostenlijn kan klikken en de onderliggende transacties ziet — met een “terug”-knop om naar de samenvatting te keren.
Oefening 7 — Marktmandeanalyse (Gevorderd)
Scenario: Een Nederlandse online retailer wil cross-sell-aanbevelingen verbeteren. Welke producten worden het vaakst samen gekocht? U gebruikt het Apriori-algoritme om associatieregels te vinden.
Dataset: De UCI Online Retail-dataset uit oefening 3 werkt hier uitstekend.
Stappen:
1. Installeer de bibliotheek mlxtend in Python: pip install mlxtend.
2. Zet de transactiedata om naar een mandemix (rijen = facturen, kolommen = producten, waarden = 1/0):
import pandas as pd
from mlxtend.frequent_patterns import apriori, association_rules
basket = df.groupby(['InvoiceNo', 'Description'])['Quantity'].sum().unstack().fillna(0)
basket = basket.applymap(lambda x: 1 if x > 0 else 0)
frequent_items = apriori(basket, min_support=0.02, use_colnames=True)
rules = association_rules(frequent_items, metric='lift', min_threshold=1.5)
rules = rules.sort_values('lift', ascending=False)
print(rules[['antecedents','consequents','support','confidence','lift']].head(20))
- Interpreteer de topregels: een lift > 2 betekent dat klanten die product A kopen twee keer zo vaak product B kopen in vergelijking met willekeurige kans.
- Visualiseer de top 10 regels als een bellendiagram in Power BI: X = support, Y = confidence, belgrootte = lift.
Verwachte output: Een gerangschikte lijst van productparen met lift-scores. Het e-commerceteam gebruikt dit om “vaak samen gekocht”-aanbevelingen te configureren — zonder dat een machine learning-leverancier nodig is.
Oefening 8 — Churnvoorspellingsdashboard (Gevorderd)
Scenario: Een telecomreseller in Eindhoven verliest jaarlijks 8% van zijn klanten. De commercieel directeur wil weten welke klanten de komende 90 dagen waarschijnlijk zullen churnen — voordat ze daadwerkelijk vertrekken.
Dataset: Gebruik de IBM Telco Customer Churn-dataset van Kaggle — 7.043 klanten, vrij beschikbaar.
Stappen:
1. Train in Python een logistisch regressiemodel:
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import pandas as pd
df = pd.read_csv('telco_churn.csv')
df['Churn'] = df['Churn'].map({'Yes': 1, 'No': 0})
# Codeer categorische variabelen
for col in df.select_dtypes('object').columns:
df[col] = LabelEncoder().fit_transform(df[col].astype(str))
X = df.drop(['customerID', 'Churn'], axis=1)
y = df['Churn']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
model = LogisticRegression(max_iter=1000)
model.fit(X_train, y_train)
df['churn_probability'] = model.predict_proba(X)[:, 1]
- Exporteer de gescoorde klanttabel naar CSV.
- Laad in Power BI en bouw een dashboard: verdeling van churnkansen, top 50 at-risk-klanten op omzet en belangrijkste churndrijvers (feature importances gevisualiseerd als staafdiagram).
- Voeg een kolom “risiconiveau” toe: Hoog (>70%), Gemiddeld (40–70%), Laag (<40%).
Verwachte output: Het commerciële team heeft een wekelijkse actielijst — 50 klanten om te bellen, gerangschikt op omzet die op het spel staat. Geen model. Een actielijst.
Oefening 9 — Realtime monitoringopzet (Expert)
Scenario: Een productiefabriek in Tilburg monitort 200 sensoren op de productielijn. Stilstand kost €4.000 per uur. U bouwt een realtime monitoringdashboard dat een melding geeft wanneer een sensorwaarde de drempelwaarde overschrijdt.
Dataset: Gebruik Python om streamingsensordata te simuleren, of maak verbinding met een gratis MQTT-broker met IoT-voorbeelddata.
Stappen:
1. Simuleer een streamingdatabron in Python:
import time, random, json
sensors = ['temp_01','pressure_02','vibration_03']
while True:
reading = {
'timestamp': pd.Timestamp.now().isoformat(),
'sensor': random.choice(sensors),
'value': random.gauss(50, 10)
}
print(json.dumps(reading))
time.sleep(1)
- Push data naar Azure Event Hub of een PostgreSQL-tabel met een tijdstempelindex.
- Verbind Power BI met de streamingdataset (Power BI Streaming Dataset API).
- Bouw een realtime lijndiagram dat elke 5 seconden bijwerkt.
- Configureer een Power BI-melding: als een sensorwaarde 70 overschrijdt, stuur een e-mail naar de plantmanager.
Verwachte output: Een live dashboard zichtbaar op een scherm in de fabriek. Wanneer een sensor piekt, wordt binnen 30 seconden een melding verstuurd — voordat de lijn stilvalt.
Uitdaging voor gevorderden: Voeg een voortschrijdend gemiddelde van 5 minuten toe om echte anomalieën te onderscheiden van willekeurige ruis. Eén enkele piek is ruis. Drie opeenvolgende metingen boven de drempelwaarde is een signaal.
Oefening 10 — Volledige BI-strategiesimulatie (Expert)
Scenario: U bent de pas aangestelde Head of Analytics bij een Nederlands distributiebedrijf van €45 miljoen. Het board wil een BI-roadmap voor de komende 18 maanden. U heeft 90 minuten om uw plan te presenteren.
Dit is geen technische oefening. Het is een strategische.
Stappen:
1. Definieer de boardvragen. Schrijf vijf vragen die het board daadwerkelijk stelt: Welke klanten hebben een negatieve marge? Waar verliezen we van concurrenten? Hoe ziet onze cashpositie er over 90 dagen uit?
2. Breng data-assets in kaart. Inventariseer wat er bestaat: ERP (SAP B1), CRM (Salesforce), spreadsheets. Beoordeel elke bron: compleet, gedeeltelijk of ontbrekend.
3. Prioriteer use cases. Scoor elke boardvraag op twee assen: zakelijke impact (1–5) en databereidheid (1–5). Zet uit op een 2×2-matrix. Rechtsboven kwadrant = begin hier.
4. Definieer het KPI-contract. Schrijf voor uw prioritaire use case een formele KPI-definitie:
– Metric: Brutomarge per klant
– Teller: Omzet minus COGS (per klant, per periode)
– Noemer: Omzet (per klant, per periode)
– Granulariteit: Klant × Maand
– Uitsluitingen: Interne overdrachten, creditnota’s ouder dan 90 dagen
– Afstemmingscontrole: De som van alle klantmarges moet gelijk zijn aan de brutomarge op bedrijfsniveau in de winst-en-verliesrekening
5. Bouw een 3-fasen-roadmap: Fundament (maanden 1–3: datakwaliteit, één live dashboard), Inzicht (maanden 4–9: forecasting, segmentatie), Intelligentie (maanden 10–18: predictieve modellen, geautomatiseerde meldingen).
6. Presenteer aan het “board”. Laat een collega de CFO spelen en elke aanname uitdagen.
Verwachte output: Een eenpagina-BI-roadmap met geprioriteerde use cases, KPI-definities en een gefaseerd leveringsplan. Dit is de deliverable die een BI-consultancybureau in week één van een opdracht produceert.
Wat we consistent zien in Benelux-implementaties: bedrijven die KPI-contracten definiëren vóórdat ze dashboards bouwen, verminderen herwerk met meer dan de helft. De discipline van het opschrijven van een teller en noemer dwingt gesprekken af die anders zes maanden later aan de oppervlakte zouden komen — wanneer de CFO vraagt waarom het BI-getal niet overeenkomt met het financegetal.
Als uw organisatie zich in deze fase bevindt — het in kaart brengen van data-assets en het prioriteren van use cases — beschrijft de Data Foundation-oplossing hoe we dat voorwerk met klanten structureren.

Hoe structureert u uw BI-leerpad?
22,7% van de Nederlandse ondernemingen met 10 of meer medewerkers maakte in 2024 gebruik van AI — een stijging ten opzichte van 14% het jaar daarvoor, aldus CBS. Die adoptie-kloof creëert een vaardigheidskloof. De organisaties die deze het snelst dichten, zijn niet degenen die meer tools aanschaffen. Het zijn degenen die interne analytische spierkracht opbouwen via doelbewuste oefening.
Zo structureert u die oefening.
Progressie van beginner naar gemiddeld naar gevorderd
| Niveau | Oefeningen | Doorstroomcriteria |
|---|---|---|
| Beginner | 1–2 | Kan een gefilterd dashboard bouwen; kan een KPI-anomalie definiëren en markeren |
| Gemiddeld | 3–5 | Kan SQL-joins schrijven; kan klanten segmenteren; kan een forecast met betrouwbaarheidsintervallen produceren |
| Gevorderd | 6–8 | Kan een financieel rapport automatiseren; kan een Python ML-model uitvoeren; kan associatieregels interpreteren |
| Expert | 9–10 | Kan een live monitoringsysteem ontwerpen; kan een BI-strategie presenteren aan een board |
Haast u niet door de doorstroomcriteria. Oefening 3 afronden zonder uw RFM-scoringslogica te kunnen uitleggen aan een niet-technische manager, betekent dat u nog niet klaar bent voor oefening 4.
Aanbevolen tools per niveau
| Niveau | Aanbevolen tools | Waarom |
|---|---|---|
| Beginner | Excel, Power BI Desktop | Lage drempel, visuele feedback, geen programmeerkennis vereist |
| Gemiddeld | SQL (PostgreSQL of SQL Server), Power BI | Joins en aggregaties zijn de kern van BI; Power BI maakt rechtstreeks verbinding |
| Gevorderd | Python (pandas, scikit-learn, mlxtend), Power BI | ML-modellen vereisen code; Power BI visualiseert de outputs |
| Expert | Alle bovenstaande + Azure / AWS streaming | Realtime en strategisch werk vereist infrastructuurbewustzijn |
Als u Power BI gebruikt, begin dan met oefening 1. Als uw primaire tool SQL is, begin dan met oefening 2. Als u in Python werkt, ga dan direct naar oefening 3 en gebruik de SQL-stappen als referentie.
Zelfevaluatielijst
Bevestig vóór het doorgaan naar het volgende niveau dat u al het volgende kunt doen zonder de syntax op te zoeken:
Beginner:
– [ ] Een CSV verbinden met Power BI en een datumhiërarchie bouwen
– [ ] Een Top N-filter toepassen op een staafdiagram
– [ ] Een KPI definiëren met teller, noemer en tijdvenster
– [ ] Een voorwaardelijke formule schrijven in Excel (IF, AVERAGEIF)
Gemiddeld:
– [ ] Een SQL-query schrijven met GROUP BY, HAVING en een vensterfunctie (LAG, NTILE)
– [ ] Een RFM-model bouwen vanuit een transactietabel
– [ ] Een 12-maandenforecast produceren met betrouwbaarheidsintervallen
– [ ] Power BI verbinden met een live SQL-database
Gevorderd:
– [ ] Een SQL-view bouwen die een winst-en-verliesberekening automatiseert
– [ ] Een Apriori-associatieregelsmodel uitvoeren in Python
– [ ] Een logistisch regressiechurnmodel trainen en scoren
– [ ] Modeloutputs interpreteren voor een niet-technisch publiek
Expert:
– [ ] Een streaming data pipeline ontwerpen
– [ ] Een formeel KPI-contract schrijven met afstemmingscontrole
– [ ] BI-use cases prioriteren via een impact × bereidheidsmatrix
– [ ] Een 18-maanden-BI-roadmap presenteren aan een board
Het Scenario-to-Signal-framework
De meeste BI-projecten mislukken niet door slechte tools, maar door slechte vragen. Het Scenario-to-Signal-framework is een vijfstappenstructuur die ervoor zorgt dat elke oefening — en elke echte klantopdracht — begint met een beslissing, niet met een dataset.
Bron: Branche-inschattingen, indicatieve cijfers
Dit is wat operationele ervaring laat zien: organisaties die stap 1 overslaan (boardvraag eerst) bouwen consequent dashboards die vragen beantwoorden die niemand heeft gesteld. Het dashboard ziet er indrukwekkend uit. Niemand gebruikt het.
Stap 1 — Boardvraag eerst. Schrijf de directievraag in één zin: Welke klanten veroorzaken margeërosie en waarom? Definieer de beslissing die dit mogelijk maakt: Prioriteer de top 20 accounts voor een prijsherziening.
Stap 2 — Metric-contract. Definieer 3–7 KPI’s met strikte teller/noemer-definities, analytische granulariteit, tijdvenster en uitsluitingen. Voeg één afstemmingscontrole toe aan een financiële bron van waarheid.
Stap 3 — Data-naar-granulariteitskartering. Inventariseer uw datasets. Kies de analytische granulariteit (orderregel, dag, klant). Schrijf een joinplan. Voer de belangrijkste integriteitschecks uit: duplicaten, ontbrekende externe sleutels, één-op-veel-valkuilen.
Stap 4 — Inzichtpatroonopbouw. Pas één van vijf patronen toe: Trend, Afwijking-van-plan, Segment, Funnel of Forecast/What-if. Valideer met gevoeligheidscontroles — verander een filter, verander een tijdvenster, verwijder de grootste uitbijter. Houdt het inzicht stand?
Stap 5 — Beslissings- en actielus. Zet outputs om in een actiememo: eigenaar, actie, verwachte €-impact, betrouwbaarheidsniveau, volgende benodigde data. Leg vast wat u heeft geleerd. Gebruik dit in de volgende oefeniteratie.
Het patroon in onze klantopdrachten is duidelijk: teams die hun KPI-contracten documenteren in stap 2, besteden aanzienlijk minder tijd aan herwerk tijdens de leveringsfase. De discipline is aanvankelijk ongemakkelijk. Het betaalt zichzelf terug tegen de tweede sprint.
Voor teams die klaar zijn om van oefeningen naar live implementatie te gaan, behandelt de Commercial Intelligence-oplossing hoe we dit framework toepassen op verkoop- en klantanalyse voor Benelux-kmo’s. En als u wilt begrijpen hoe het volledige leveringstraject eruitziet, brengt het Data-to-Done Framework de zeven fasen in kaart van probleemdefiniëring tot productie.
Klaar om deze oefeningen toe te passen op een echt zakelijk probleem? Boek een gratis kennismakingsgesprek en vertel ons over uw huidige datasituatie — wij vertellen u welke oefeningen aansluiten bij uw meest urgente boardvragen.
Wij hebben BI-implementaties begeleid in de maakindustrie, logistiek, professionele dienstverlening en retail in de Benelux. Ons diagnostisch proces begint met dezelfde stap 1-vraag die u in oefening 10 heeft geoefend: welke beslissing moet deze data mogelijk maken?

Belangrijkste inzichten
- Begin met de boardvraag, niet met de dataset. Elke oefening in deze gids opent met een bedrijfsscenario omdat de vraag de metric, de granulariteit en de tool bepaalt — niet andersom.
- De progressie van beginner naar expert is een doorstroomsysteem, geen tijdlijn. Overstappen naar RFM-segmentatie voordat u een SQL
GROUP BYkunt schrijven, levert modellen op die u niet kunt uitleggen of verdedigen. - 22,7% van de Nederlandse ondernemingen gebruikte AI in 2024, tegenover 14% in 2023 (CBS) — de organisaties die nu analytische vaardigheden opbouwen, positioneren zich vóór de adoptiecurve, niet erachteraan.
- Een KPI-contract (teller, noemer, granulariteit, uitsluitingen, afstemmingscontrole) voorkomt de meest voorkomende BI-fout: het getal van de CFO en het dashboardgetal komen niet overeen.
- Oefeningen 7, 8 en 9 vereisen Python. Als u daar nog niet bent, is dat het duidelijkste signaal waar u uw volgende 30 uur leertijd in moet investeren.
Veelgestelde vragen
Wat zijn business intelligence oefeningen?
Business intelligence oefeningen zijn gestructureerde, scenariogebaseerde praktijkproblemen die analisten en managers trainen om ruwe data om te zetten in zakelijke beslissingen. Ze omvatten het aanmaken van dashboards, KPI-analyse, klantsegmentatie, forecasting en strategische BI-planning. Door ze te oefenen bouwt u het oordeelsvermogen op dat tools alleen niet kunnen bijbrengen.
Wat is de beste BI-oefening voor beginners?
De beste startoefening voor beginners is het aanmaken van een verkoopdashboard in Excel of Power BI Desktop met een CSV-voorbeelddataset. Het leert u data laden, berekende kolommen, visueel ontwerp en filteren — de vier fundamenten van elke BI-deliverable — in 2–3 uur zonder dat programmeerkennis vereist is.
Hoe oefen ik business intelligence-vaardigheden zonder echte bedrijfsdata?
Gebruik vrij beschikbare datasets: de UCI Online Retail-dataset (541.909 transacties), de Microsoft Northwind-database (orders, producten, leveranciers), de IBM Telco Churn-dataset (7.043 klanten) en Microsoft’s AdventureWorks Power BI-voorbeeldbestanden. Ze zijn allemaal gestructureerd rond realistische bedrijfsscenario’s.
Welke SQL-vaardigheden heb ik nodig voor BI-oefeningen?
Voor gemiddelde BI-oefeningen heeft u SELECT, GROUP BY, HAVING, JOIN (inner en left) en vensterfuncties (LAG, LEAD, NTILE, ROW_NUMBER) nodig. Gevorderde oefeningen voegen CREATE VIEW, CTE’s (WITH) en subqueries toe. Oefen deze in PostgreSQL of SQL Server — beide hebben gratis versies.
Hoe lang duurt het om alle 10 BI-oefeningen te voltooien?
Het doorwerken van alle 10 oefeningen kost ongeveer 40–50 uur gerichte oefening. Beginners mogen verwachten meer tijd te besteden aan oefeningen 1–2 (de tools begrijpen) en oefeningen 9–10 (de architectuur begrijpen). Verspreid over 8–10 weken is dat een realistische bijscholingstijdlijn voor iemand met een voltijdse functie.
Wat is RFM-analyse en waarom is het een BI-oefening?
RFM staat voor Recency, Frequency, Monetary. Het is een klantsegmentatietechniek die elke klant scoort op hoe recent ze hebben gekocht, hoe vaak ze kopen en hoeveel ze besteden. Het is een kern-BI-oefening omdat het SQL-aggregatie, scoringslogica en een bedrijfsgericht resultaat (segmentgebaseerde marketingacties) vereist — allemaal in één probleem.
Kunnen deze BI-oefeningen worden gebruikt voor teamtraining?
Ja. Oefeningen 1–5 werken goed als gestructureerde teamworkshops van 3–4 uur elk. Oefening 10 (Volledige BI-strategiesimulatie) is bijzonder effectief als teamoefening: verdeel in groepen, wijs de “board”-rol toe aan een senior manager en laat elke groep hun BI-roadmap presenteren. De nabespreking brengt KPI-meningsverschillen aan het licht die anders maanden zouden kosten om te ontdekken in een live project.
Gerelateerde artikelen
- Het Data-to-Done Framework: 7 fasen van aangepaste AI-ontwikkeling — begrijp het volledige leveringstraject van zakelijk probleem tot productiesysteem
- Supply Chain 4.0: De toekomst van geautomatiseerde ketens — hoe BI en automatisering samenkomen in Benelux-logistiek en -distributie
- Vijf signalen dat u de standaard AI-tools bent ontgroeid — signalen dat uw BI-praktijk zo volwassen is geworden dat generieke tools knelpunten creëren
- De AI-paradox: waarom de meeste AI-investeringen mislukken — wat organisaties die BI opschalen onderscheidt van degenen die vastzitten in pilotmodus
Bronnen
- Increasing use of AI by business — CBS (Centraal Bureau voor de Statistiek), september 2025
- ICT usage in Enterprises — CBS, 2024
- ICT and e-commerce in enterprises — Statbel (Belgisch Statistisch Bureau), 2024
- ICT usage in enterprises — European Commission (Netherlands) — Eurostat, 2024
- ICT usage in enterprises — European Commission (Belgium) — Eurostat, 2024
- Quality report on European statistics on ICT usage and e-commerce — Eurostat, 2026
- Digital Consumer Trends 2024 — Deloitte België, november 2024
- FY24 Annual Results — Deloitte België, januari 2024
- Integrated Annual Report 2024/2025 — Deloitte Nederland, 2024–2025
- Gartner identifies top trends in data and analytics for 2025 — Digitalisation World (met verwijzing naar Gartner), 2025
- Gartner’s top D&A predictions for 2025 — DataGalaxy (met verwijzing naar Gartner), juli 2024
- Augmented Analytics Market Size and Share 2025–2030 — Next Move Strategy Consulting, 2024
- Everything-as-a-service business models — Deloitte België