

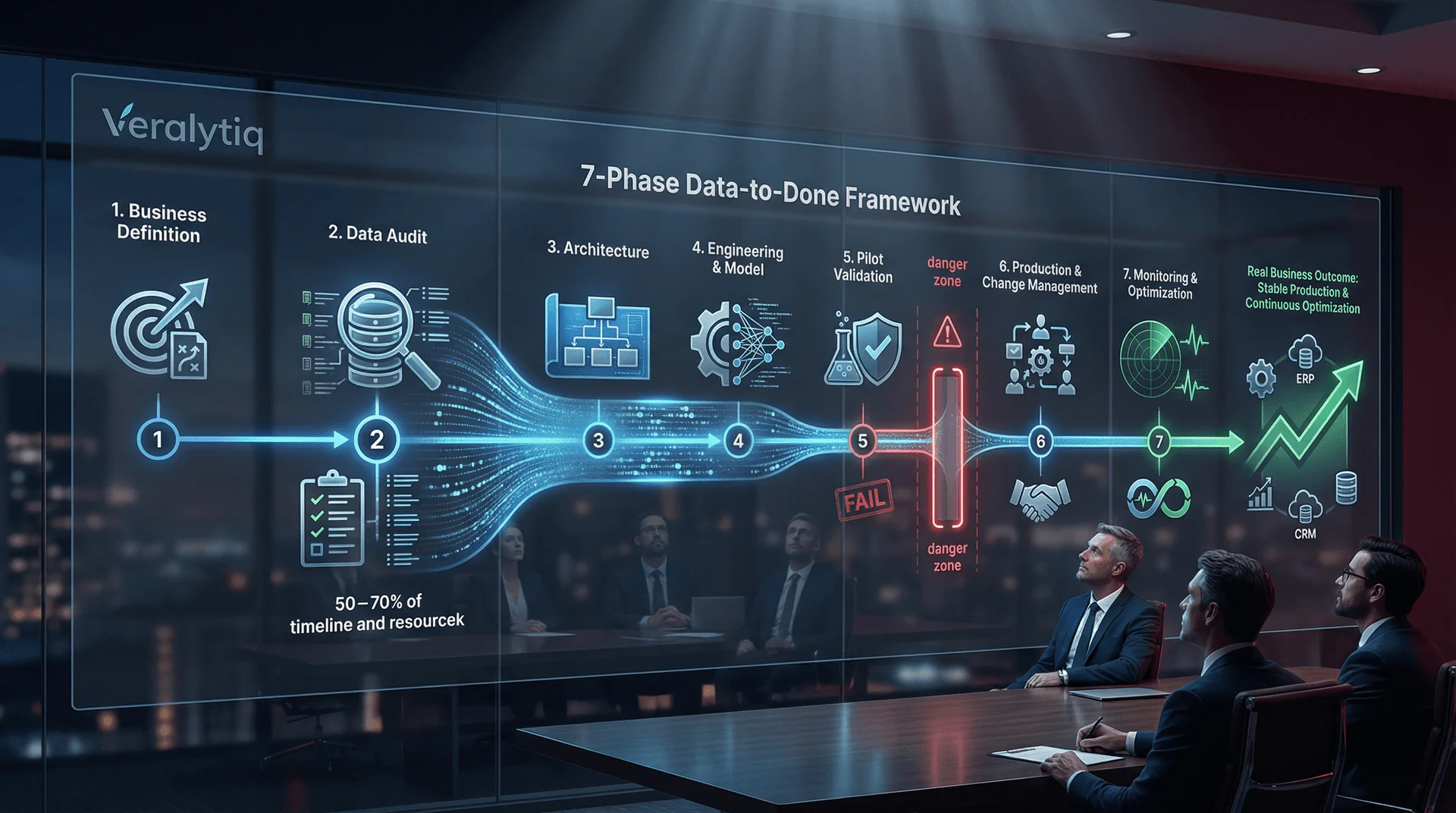

Maatwerk AI-ontwikkeling volgt zeven duidelijke fasen van bedrijfsprobleemdefinitiie tot productie-implementatie en continue optimalisatie. Datagereedheid neemt 50–70% van de totale projecttijdlijn in beslag, de overgang van pilot naar productie is het stadium waarin 88% van de AI-projecten vastloopt of sterft, en de organisaties die slagen investeren evenveel in verandermanagement als in modelontwikkeling. Dit artikel biedt de complete fase-voor-fase blauwdruk die de 26% van de bedrijven die AI opschalen volgen — en die de overige 74% overslaan, op eigen kosten.
Waarom Methodologie Ertoe Doet: Het Pilotkerkhof
Het verschil tussen AI-projecten die ROI opleveren en projecten die op het pilotkerkhof belanden, is niet de kwaliteit van het algoritme — het is de discipline van het proces. Een gestructureerde methodologie is de meest betrouwbare voorspeller van AI-projectsucces.
De cijfers zijn ontnuchterend. Gartner voorspelde dat 30% van de generatieve AI-projecten na proof of concept zou worden verlaten tegen eind 2025. S&P Global bevestigde dat 42% van de bedrijven de meeste AI-initiatieven in 2025 heeft opgegeven, tegenover 17% in 2024. McKinsey rapporteert dat bijna acht op de tien bedrijven generatieve AI hebben ingezet, maar vrijwel hetzelfde aandeel geen materiële impact op de winst zag.
Het patroon is consistent: organisaties springen van “we moeten AI gebruiken” naar “laten we een model bouwen” zonder de tussenstappen die het succes bepalen — probleemdefinitiie, data-audit, architectuurontwerp, verandermanagementplanning. Het resultaat is technisch functionele AI die geen bedrijfswaarde levert, prototypes die niet kunnen opschalen, en dure experimenten die het vertrouwen van stakeholders in toekomstige AI-investeringen ondermijnen.
Het Data-to-Done framework adresseert dit rechtstreeks. Elke fase heeft gedefinieerde inputs, outputs, beslispoorten en succescriteria. Geen enkele fase is optioneel. Een fase overslaan bespaart geen tijd; het leent tijd van de toekomst tegen samengestelde rente. Organisaties die MLOps en datagovernance formaliseren, verkorten de time-to-production van modellen met 40%.
Fase 1: Bedrijfsprobleem Definitie & Use Case Selectie
Elk succesvol AI-project begint met een bedrijfsprobleem, niet met een technologie. Fase 1 vertaalt een strategische uitdaging naar een precies afgebakende AI use case met meetbare succescriteria, een gedefinieerde stakeholder en een heldere verbinding met omzet, kosten of risico.
De meest voorkomende fout bij AI-adoptie is beginnen met de technologie: “We hebben een machine learning-model nodig” of “We moeten GPT ergens voor gebruiken.” Sectoronderzoek toont consequent aan dat beginnen met technologie in plaats van bedrijfsproblemen een primaire oorzaak is van AI-falen. Fase 1 draait dit om door te eisen dat het bedrijfsprobleem eerst komt, en de technologieselectie wacht tot Fase 3.
Kernactiviteiten: Stakeholderinterviews om de bedrijfsproblemen met de hoogste impact te identificeren. ROI-schatting voor elke kandidaat-use case. Haalbaarheidsanalyse: bestaan de vereiste data, en zijn ze toegankelijk? Use case-prioritering met behulp van een impact-haalbaarheidsmatrix. Definitie van succesmetrieken die het bedrijf — niet het datateam — zal meten.
Fase-output: Een enkele, precies afgebakende use case met een gedocumenteerde probleemstelling, succesmetriek, executive sponsor en geschatte ROI. De use case moet smal genoeg zijn om meetbare resultaten te leveren binnen 90 dagen, maar strategisch significant genoeg om de investering te rechtvaardigen.
Tijdlijn: 1–2 weken. Budgetallocatie: 5–10% van de totale projectinvestering.
Beslispoort: Ga alleen verder als de use case executive sponsorship heeft, een kwantificeerbaar succescriterium en bevestigde databeschikbaarheid. Als een element ontbreekt, itereer — sla niet vooruit.
Fase 2: Data-audit & Gereedheidsanalyse
Fase 2 is de belangrijkste fase in het gehele framework — en de meest onderschatte. Datagereedheid bepaalt of een maatwerk AI-project slaagt, en organisaties die deze fase overhaasten vormen het merendeel van het 70–80% faalpercentage.
70% van de AI-falen vindt zijn oorsprong in onopgeloste dataproblemen. Het onderzoek van Informatica identificeert datakwaliteit als het belangrijkste obstakel voor 43% van de organisaties.Succesvolle AI-programma’s investeren 50–70% van hun budget en tijdlijn in datagereedheid — een verhouding die organisaties schokt die verwachten het merendeel van hun budget aan het AI-model zelf te besteden.
Kernactiviteiten: Uitgebreide data-inventarisatie over alle relevante systemen. Beoordeling van datakwaliteit: volledigheid (doel >90%), nauwkeurigheid, consistentie, actualiteit. Gap-analyse: welke data ontbreken, en hoe worden hiaten aangepakt? Audit van datatoegang: kan het AI-systeem de data programmatisch benaderen? Privacy- en compliancereview: AVG-implicaties, dataresidentie-eisen, toestemmingsstatus. Datagovernance-basislijn: wie is eigenaar van elke databron, en wat zijn de updatefrequenties?
De audit levert een Data Quality Scorecard op die elke databron beoordeelt op volledigheid, nauwkeurigheid, consistentie en actualiteit. Bronnen die onder 70% scoren vereisen remediatie voordat modelontwikkeling begint. Dit is geen bureaucratie — het is risicomanagement. Een model dat is getraind op onvolledige of inconsistente data produceert onbetrouwbare outputs, ongeacht hoe geavanceerd het algoritme is.
Fase-output: Data Quality Scorecard, remediatieplan met tijdlijn, data-architectuurdiagram, privacy- en compliancegoedkeuring.
Tijdlijn: 2–4 weken. Budgetallocatie: 20–30% van de totale projectinvestering.
Beslispoort: Ga alleen verder wanneer kritieke databronnen boven 70% scoren op de Data Quality Scorecard, of wanneer een remediatieplan met een gedefinieerde tijdlijn is goedgekeurd. Als datagereedheid fundamenteel ontoereikend is, herstructureer de use case rond beschikbare data in plaats van een onklare dataset in productie te forceren.
Fase 3: Oplossingsarchitectuur & Technologieselectie
Fase 3 ontwerpt de technische blauwdruk: welke AI-benadering past bij de use case, welke infrastructuur ondersteunt deze, hoe de oplossing integreert met bestaande systemen, en hoe deze opschaalt van pilot naar productie zonder een herbouw te vereisen.
Deze fase beantwoordt de “bouwen vs. kopen vs. fine-tunen”-vraag met data, niet met aannames. De architectuur moet rekening houden met huidige datavolumes en verwachte groei, integratiepunten met bestaande ERP-, CRM- en operationele systemen, beveiligings- en compliance-eisen inclusief EU AI Act-verplichtingen, latentie-eisen voor real-time versus batchverwerking, en het vermogen van het team om het systeem na implementatie te onderhouden en bij te werken.
Kernactiviteiten: Technologie-evaluatie: cloudplatformselectie (Azure, AWS, GCP), AI/ML-frameworkselectie, beoordeling van integratie-middleware. Architectuurontwerp: datapipelines, model serving-infrastructuur, monitoringdashboards, API-ontwerp voor systeemintegratie. Beveiligingsarchitectuur: dataversleuteling, toegangscontroles, auditlogging. Compliance-architectuur: transparantiemechanismen, framework voor biastesten, protocollen voor menselijk toezicht.
Fase-output: Oplossingsarchitectuurdocument, technologie-stackspecificatie, integratie-ontwerp, beveiligings- en complianceframework, schatting van infrastructuurkosten.
Tijdlijn: 1–2 weken. Budgetallocatie: 10–15% van de totale projectinvestering.
Fase 4: Data Engineering & Modelontwikkeling
Fase 4 transformeert ruwe data tot een getraind AI-model — maar de nadruk ligt op engineering, niet op experimenteren. De datapipeline die het model voedt is even belangrijk als het model zelf, omdat een model zonder betrouwbare datapipeline een prototype is dat de productie niet overleeft.
Dit is de fase die de meeste mensen associëren met “AI-ontwikkeling,” maar het vertegenwoordigt doorgaans slechts 20–30% van de totale projectinspanning. De voorgaande fasen — probleemdefinitiie, data-audit, architectuurontwerp — zorgen ervoor dat de ontwikkelinspanning gericht en efficiënt is in plaats van verkennend en verspillend.
Kernactiviteiten: Constructie van de datapipeline: geautomatiseerde extractie, transformatie en laden (ETL) uit bronsystemen. Feature engineering: vertaling van ruwe data naar de variabelen die het model nodig heeft. Modelselectie en -training: keuze van de juiste AI-benadering (regressie, classificatie, NLP, computer vision) op basis van de use case-vereisten. Modelvalidatie: testen van nauwkeurigheid, precisie, recall en bias tegen de succescriteria gedefinieerd in Fase 1. Documentatie: modelarchitectuur, herkomst van trainingsdata, prestatiemetrieken — essentieel voor EU AI Act-compliance en doorlopend onderhoud.
Volgens een casestudy uit 2025 alloceerde een middelgroot financiële-dienstverleningsbedrijf 22% van zijn maatwerk AI-budget aan datavoorbereiding en 28% aan algoritme-ontwikkeling. Deze 50/50-verdeling tussen data engineering en modelontwikkeling is typerend voor goed gestructureerde projecten.
Fase-output: Getraind model dat voldoet aan de nauwkeurigheidsdrempels gedefinieerd in Fase 1, geautomatiseerde datapipeline, modeldocumentatie, biasbeoordelingsrapport.
Tijdlijn: 3–6 weken. Budgetallocatie: 25–35% van de totale projectinvestering.
Fase 5: Pilotimplementatie & Validatie
Fase 5 is de transitie met het hoogste risico in elk AI-project. Dit is waar het pilotkerkhof zich vult: 88% van de AI-pilots bereikt nooit de productie. Het verschil tussen de 12% die slaagt en de 88% die vastloopt is niet de modelkwaliteit — het is de implementatiediscipline.
De pilot draait in een gecontroleerde omgeving met reële data, reële gebruikers en reële bedrijfsprocessen — maar met gedefinieerde grenzen. Het is geen sandbox-demonstratie. Het is een productierepetitie. De pilot moet bewijzen dat het AI-model nauwkeurig presteert op live data, dat gebruikers effectief met het systeem kunnen interacteren, en dat het bedrijfsresultaat gedefinieerd in Fase 1 haalbaar is.
Kernactiviteiten: Implementatie van het model in een gecontroleerde productie-achtige omgeving. Uitvoering van de pilot met een gedefinieerde gebruikersgroep (doorgaans 10–20% van de eindgebruikers). Meting van prestaties tegen de Fase 1-succescriteria met live data. Verzameling van gebruikersfeedback over interface, workflow-integratie en outputkwaliteit. Identificatie van edge cases, faalmodi en datadriftpatronen. Documentatie van pilotresultaten met gekwantificeerde metrieken.
MIT’s onderzoek toont aan dat middelgrote bedrijven maatwerk AI-pilots in circa 90 dagen kunnen opschalen wanneer de scope strak is gedefinieerd. De termijn van 90 dagen is niet willekeurig — het is lang genoeg om nauwkeurigheid te valideren op reële data door seizoens- en operationele variaties heen, maar kort genoeg om stakeholdermomentum te behouden en de “permanente pilot”-val te vermijden.
Fase-output: Pilotresultatenrapport met gekwantificeerde metrieken vs. succescriteria, samenvatting van gebruikersfeedback, documentatie van edge cases, productiegeeredheidsanalyse, go/no-go-aanbeveling.
Tijdlijn: 3–4 weken. Budgetallocatie: 10–15% van de totale projectinvestering.
Beslispoort: Dit is de kritieke poort. Ga alleen door naar productie als de pilot voldoet aan of de succescriteria gedefinieerd in Fase 1 overtreft. Als de pilot tekortschiet, diagnosticeer de grondoorzaak: is het datakwaliteit (terug naar Fase 2), modelprestatie (itereer Fase 4) of workflow-fit (herontwerp de integratie)? Ga niet door naar productie met een “goed genoeg” pilot — productie vergroot elke zwakte.
Fase 6: Productie-integratie & Verandermanagement
Fase 6 brengt de gevalideerde pilot over naar volledige productie — en dit is waar de menselijke dimensie even belangrijk wordt als de technische dimensie. Een technisch uitstekend AI-systeem dat gebruikers weerstaan, wantrouwen of negeren levert nul bedrijfswaarde.
Productie-integratie betekent het inbedden van de AI-outputs rechtstreeks in de workflows waar beslissingen worden genomen. De AI draait niet in een apart dashboard en vereist geen aparte login. Het verschijnt binnen het ERP, het CRM, het warehouse management-systeem of de financiële rapportagetool die gebruikers al dagelijks gebruiken.
IMD’s 2025 AI Maturity Index concludeert dat “opschaling van AI evenveel draait om verandermanagement als om codemanagement.” Bedrijven als Unilever, Visa en Hitachi hebben tienduizenden medewerkers getraind in AI-vaardigheid — een voorwaarde voor ondernemingsbrede implementatie. Voor middelgrote bedrijven is de schaal kleiner maar het principe identiek: gebruikers moeten begrijpen wat de AI doet, de outputs vertrouwen, en weten wanneer ze moeten overrulen.
Kernactiviteiten: Volledige productie-implementatie met monitoring. Gebruikerstrainingsprogramma: wat de AI doet, hoe outputs te interpreteren, wanneer te overrulen. Communicatieplan: waarom de AI is geïmplementeerd, wat het betekent voor elke rol, wat het niet doet. Feedbackmechanisme: gestructureerde kanalen voor gebruikers om problemen te melden, verbeteringen voor te stellen en onjuiste outputs te signaleren. Prestatiemonitoring: real-time dashboards die nauwkeurigheid, latentie, gebruik en bedrijfsimpactmetrieken volgen.
Fase-output: In productie geïmplementeerd systeem, getrainde gebruikersbasis, communicatiematerialen, feedbackinfrastructuur, monitoringdashboards.
Tijdlijn: 2–3 weken. Budgetallocatie: 10–15% van de totale projectinvestering.
Fase 7: Monitoring, Optimalisatie & Opschaling
Fase 7 is geen eindpunt — het is het begin van continue verbetering. AI-modellen degraderen na verloop van tijd naarmate datapatronen verschuiven, bedrijfsprocessen evolueren en marktomstandigheden veranderen. Zonder actieve monitoring en periodieke hertraining wordt zelfs het beste AI-systeem een risico.
Modeldrift — de geleidelijke afname van nauwkeurigheid naarmate reële data afwijken van trainingsdata — is onvermijdelijk. Een vraagvoorspellingsmodel dat is getraind op data uit 2023–2024 verliest nauwkeurigheid naarmate marktomstandigheden in 2026 patronen creëren die het model nooit heeft gezien. Sectorbenchmarks tonen dat jaarlijks AI-onderhoud doorgaans 15–25% van de initiële ontwikkelingskosten bedraagt. Organisaties die slechts 10% alloceren zien prestatieverval binnen 14 maanden; organisaties die 20–25% investeren behouden en verbeteren de nauwkeurigheid continu.
Kernactiviteiten: Continue prestatiemonitoring: nauwkeurigheid, precisie, recall en bedrijfsimpactmetrieken in real-time gevolgd. Datadriftdetectie: geautomatiseerde waarschuwingen wanneer inputdataverdelingen buiten gedefinieerde drempels verschuiven. Geplande hertraining: periodieke modelupdates met nieuwe data om nauwkeurigheid te behouden. Biasmonitoring: doorlopende testen op demografische of databronbiases die kunnen opduiken naarmate gebruik opschaalt. Opschalingsevaluatie: identificatie van nieuwe use cases, nieuwe databronnen en uitbreidingsmogelijkheden op basis van productieprestatiedata.
IDC-onderzoek rapporteert een gemiddelde ROI van $ 3,70 voor elke geïnvesteerde dollar in AI, waarbij toppresteerders rendementen van $ 10,30 per dollar realiseren. Het verschil tussen gemiddelde en toppresterende rendementen is grotendeels toe te schrijven aan Fase 7-discipline: toppresteerders optimaliseren, hertrainen en breiden hun AI-systemen continu uit, terwijl gemiddelde presteerders implementeren en vergeten.
Fase-output: Monitoringdashboards, hertrainingsschema, datadriftwaarschuwingen, kwartaalrapportages over prestaties, opschalingsroadmap.
Tijdlijn: Doorlopend. Budgetallocatie: 15–25% van de initiële investering per jaar.
Tijdlijnoverzicht: Het 90-Dagenpad
Voor een strak afgebakend middelgroot AI-project levert het Data-to-Done framework een gevalideerd, in productie geïmplementeerd AI-systeem in circa 90 dagen — aanzienlijk sneller dan het 18-maanden gemiddelde voor grote ondernemingen dat Gartner rapporteert.
| Fase | Doorlooptijd | Budget % | Belangrijkste Output |
|---|---|---|---|
| 1. Bedrijfsprobleem Definitie | 1–2 weken | 5–10% | Afgebakende use case + succescriterium |
| 2. Data-audit & Gereedheid | 2–4 weken | 20–30% | Data Quality Scorecard |
| 3. Oplossingsarchitectuur | 1–2 weken | 10–15% | Architectuurdocument |
| 4. Data Engineering & Model | 3–6 weken | 25–35% | Getraind model + pipeline |
| 5. Pilotimplementatie | 3–4 weken | 10–15% | Pilotresultaten + go/no-go |
| 6. Productie & Verandermgmt | 2–3 weken | 10–15% | Live systeem + getrainde gebruikers |
| 7. Monitoring & Optimalisatie | Doorlopend | 15–25%/jr | Continue verbetering |
| TOTAAL (Fase 1–6) | 12–21 weken | 100% | AI-systeem in productie |
Het bereik van 12–21 weken weerspiegelt de variabiliteit in datagereedheid. Organisaties met schone, toegankelijke data doorlopen Fase 2 in twee weken en het hele framework in circa 12 weken. Organisaties die significante dataremediatie nodig hebben besteden vier weken aan Fase 2 en langer aan Fase 4, waardoor het totaal wordt verlengd tot 21 weken. Hoe dan ook, dit is drastisch sneller dan het 18-maanden gemiddelde voor grote ondernemingen — omdat het framework de verspilde tijd elimineert die wordt veroorzaakt door onduidelijke probleemdefinitiie, voortijdige modelontwikkeling en ongeplande herbewerkingen.
Wat de Data-to-Done Aanpak Anders Maakt
Het Data-to-Done framework is geen theoretisch model — het is een uitvoeringsmethodologie ontworpen voor middelgrote bedrijven die zich geen 18-maanden tijdlijnen, miljoenenbudgetten of de luxe van falen kunnen veroorloven.
Drie principes onderscheiden dit framework van generieke AI-implementatiegidsen:
Bedrijfsprobleem-eerst, niet technologie-eerst. Fase 1 dwingt het gesprek te beginnen met omzet, kosten of risico — niet met algoritmen, platformen of trends. Deze afstemming waarborgt dat elke volgende fase een gedefinieerd bedrijfsresultaat dient. MIT’s onderzoek bevestigt dat leveranciersgeleide implementaties in 67% van de gevallen slagen versus 33% bij interne builds — en de primaire onderscheidende factor is deze bedrijfsprobleem-eerst-discipline.
Data-investering vóór modelinvestering. Fase 2 ontvangt de grootste enkelvoudige budgetallocatie (20–30%) omdat datakwaliteit de primaire determinant is van AI-succes. Organisaties die de data-audit overslaan of inkorten betalen ervoor in Fase 4 (onderprestatie van het model), Fase 5 (pilotfalen) of Fase 7 (productiedrift). Vooraf investeren is goedkoper dan later herwerken.
Beslispoorten, geen hooppoorten. Elke fase eindigt met een gedefinieerde beslispoort. Doorgaan, itereren of stoppen. Er is geen “laten we doorgaan en hopen dat het goed komt.” Deze gedisciplineerde aanpak voorkomt de twee duurste AI-fouten: een onderprestererend model in productie implementeren, en blijven investeren in een project dat in Fase 2 had moeten worden gestopt.
Met Nederlandse subsidies via WBSO die 30–40% van de AI R&D-kosten dekken, varieert de effectieve investering voor een middelgroot Data-to-Done project van € 35.000 tot € 100.000 — met een typische terugverdientijd van 6–12 maanden op basis van het bedrijfsresultaat dat in Fase 5 is gevalideerd.
Veelgestelde Vragen
Hoe lang duurt een maatwerk AI-project?
Met het Data-to-Done framework duurt een goed afgebakend middelgroot project 12–21 weken van probleemdefinitiie tot productie-implementatie. MIT’s data bevestigt dat middelgrote bedrijven maatwerk AI-pilots in circa 90 dagen opschalen. De tijdlijn hangt primair af van datagereedheid: organisaties met schone, toegankelijke data implementeren sneller.
Wat zijn de fasen van AI-ontwikkeling?
De zeven fasen zijn: (1) Bedrijfsprobleem Definitie, (2) Data-audit & Gereedheid, (3) Oplossingsarchitectuur, (4) Data Engineering & Modelontwikkeling, (5) Pilotimplementatie & Validatie, (6) Productie-integratie & Verandermanagement, en (7) Monitoring, Optimalisatie & Opschaling. Elke fase heeft gedefinieerde inputs, outputs en beslispoorten.
Waarom duurt datagereedheid zo lang?
50–70% van de AI-projecttijdlijnen wordt besteed aan datavoorbereiding omdat de data van de meeste organisaties verspreid is over systemen, inconsistent is geformateerd en onvolledig is gedocumenteerd. De data-audit identificeert deze problemen vroegtijdig, en het remediatieplan adresseert ze voordat modelontwikkeling begint — waarmee veel duurdere herbewerkingen later worden voorkomen.
Wat gebeurt er als de pilot faalt?
Een pilot die niet aan de succescriteria voldoet is geen mislukking — het is een diagnostisch signaal. De beslispoort bij Fase 5 vereist een grondoorzaakanalyse: is het probleem datakwaliteit (terug naar Fase 2), modelprestatie (itereer Fase 4) of workflow-integratie (herontwerp de implementatie)? Gedisciplineerde iteratie is goedkoper dan voortijdige productie-implementatie.
Heb ik een data science-team nodig om dit framework te volgen?
Nee. Het framework is ontworpen voor implementatie met een gespecialiseerde externe partner. MIT’s onderzoek toont aan dat leveranciersgeleide implementaties twee keer zo vaak slagen als interne builds. Wat u intern nodig heeft is een technisch onderlegd projecteigenaar die het bedrijfsprobleem kan definiëren, resultaten kan evalueren en het partnerschap kan managen.
Hoeveel kost elke fase?
Voor een middelgroot project varieert de totale investering van € 50.000 tot € 200.000 afhankelijk van complexiteit. Fase 2 (data-audit) en Fase 4 (modelontwikkeling) zijn samen goed voor 45–65% van het totale budget. WBSO-subsidies kunnen de effectieve kosten met 30–40% verlagen. Gedetailleerde kostenuitsplitsingen worden behandeld in Sectie 7 van deze reeks.
Wat is de verwachte ROI?
IDC-onderzoek rapporteert een gemiddelde ROI van $ 3,70 voor elke geïnvesteerde dollar in AI, waarbij toppresteerders $ 10,30 per dollar realiseren. Het Data-to-Done framework richt zich op het toppresteerderssegment door te waarborgen dat elke fase een gedefinieerd bedrijfsresultaat dient met meetbare succescriteria.
Kernpunten
— Het Data-to-Done framework bestaat uit zeven fasen: probleemdefinitiie, data-audit, architectuur, ontwikkeling, pilot, productie en monitoring — elk met gedefinieerde beslispoorten.
— 50–70% van de projecttijdlijn en 20–30% van het budget moet worden gealloceerd aan datagereedheid— de belangrijkste investering in elk AI-project.
— 88% van de AI-pilots bereikt nooit de productie; de Fase 5-beslispoort is specifiek ontworpen om voortijdige productie-implementatie te voorkomen.
— Middelgrote bedrijven die een gestructureerde methodologie gebruiken doorlopen het volledige framework in 12–21 weken — vergeleken met het 18-maanden gemiddelde voor grote ondernemingen.
— AI levert een gemiddeld rendement van $ 3,70 per geïnvesteerde dollar op, waarbij toppresteerders $ 10,30 bereiken — het verschil wordt bepaald door Fase 7-discipline (monitoring, hertraining, optimalisatie).
Bronnen
1. MIT Project NANDA — The GenAI Divide: State of AI in Business 2025, juli 2025. fortune.com
2. McKinsey & Company — Seizing the Agentic AI Advantage, juni 2025. mckinsey.com
3. BCG — AI Adoption in 2024: 74% of Companies Struggle to Achieve and Scale Value, oktober 2024. bcg.com
4. Gartner — Predicts 30% of GenAI Projects Abandoned After POC by End of 2025, juli 2024. gartner.com
5. S&P Global Market Intelligence — Voice of the Enterprise: AI & ML, Use Cases 2025. spglobal.com
6. WorkOS — Why Most Enterprise AI Projects Fail, juli 2025. Verwijst naar McKinsey & Informatica CDO Insights 2025. workos.com
7. IDC / Microsoft — Generative AI ROI Report, januari 2025. itpro.com
8. Naitive.cloud — Custom AI Models vs Off-the-Shelf: ROI Breakdown, juli 2025. blog.naitive.cloud
9. IMD — 2025 AI Maturity Index: From Pilot to Implementation at Scale, november 2025. imd.org
10. RTS Labs — Enterprise AI Roadmap: The Complete 2026 Guide, december 2025. rtslabs.com
11. Workmate — Enterprise AI Roadmap: From Pilot to Production, oktober 2025. workmate.com
12. Promethium — CDO Guide: Enterprise AI Implementation Roadmap and Timeline, oktober 2025. promethium.ai
13. MultiQoS — AI Implementation Roadmap: From Pilot to Production in 90 Days, januari 2026. multiqos.com
14. Europese Commissie — Regelgevingskader voor AI (EU AI Act). digital-strategy.ec.europa.eu
15. RVO — WBSO Subsidie. rvo.nl