

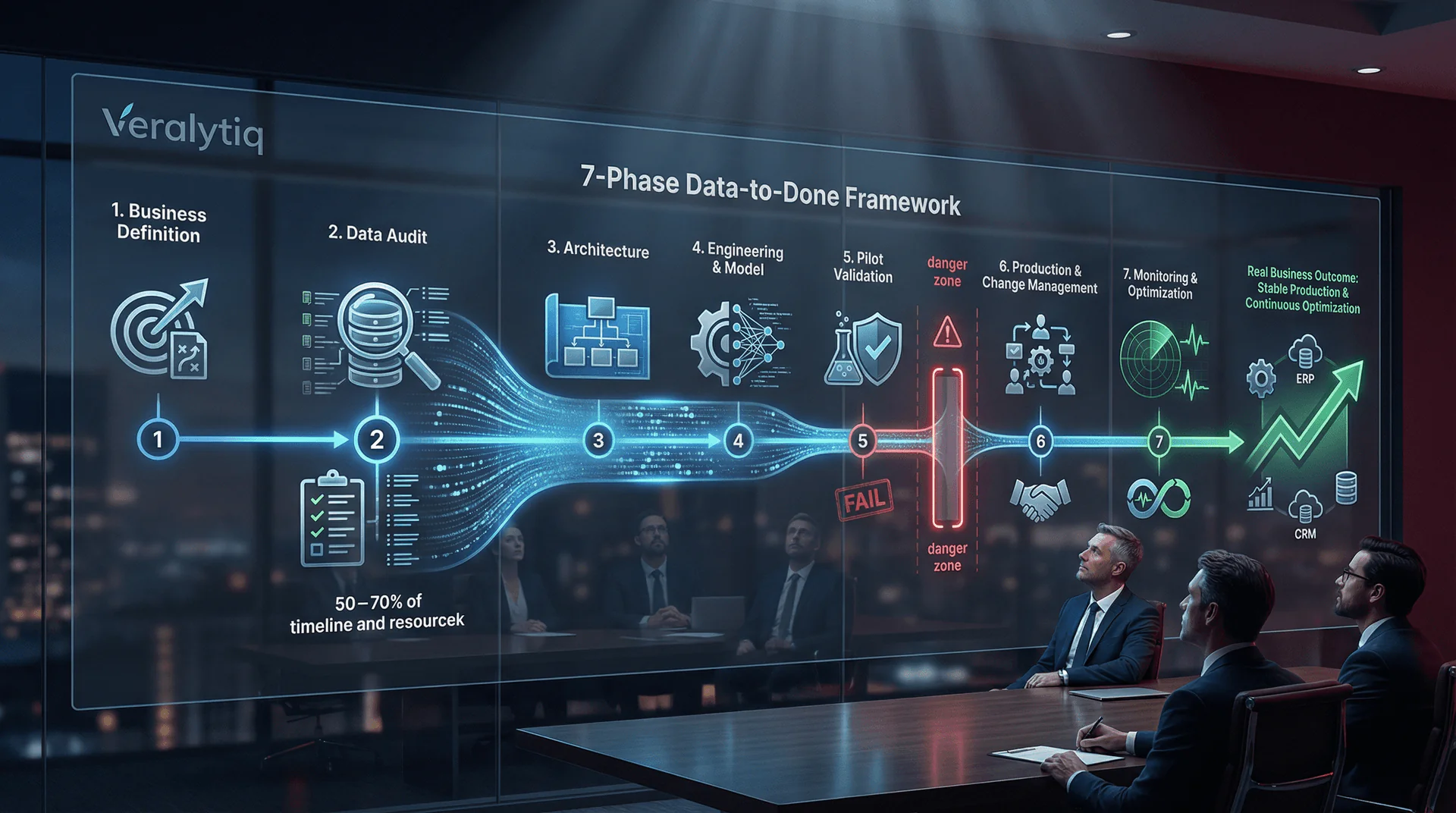

Custom AI development follows seven distinct phases from business problem definition through production deployment and continuous optimisation. Data readiness consumes 50–70% of the total project timeline, the pilot-to-production transition is the stage where 88% of AI projects stall or die, and the organisations that succeed invest as much in change management as in model development. This article provides the complete phase-by-phase blueprint that the 26% of companies achieving AI scale follow — and that the other 74% skip at their cost.
Why Methodology Matters: The Pilot Graveyard
The difference between AI projects that deliver ROI and those that join the pilot graveyard is not the quality of the algorithm — it is the discipline of the process. A structured methodology is the single most reliable predictor of AI project success.
The numbers are sobering. Gartner predicted that 30% of generative AI projects would be abandoned after proof of concept by the end of 2025. S&P Global confirmed that 42% of companies abandoned most AI initiatives in 2025, up from 17% in 2024. McKinsey reports that nearly eight in ten companies deployed generative AI, yet roughly the same proportion saw no material impact on earnings.
The pattern is consistent: organisations jump from “we should use AI” to “let’s build a model” without the intermediate steps that determine success — problem definition, data audit, architecture design, change management planning. The result is technically functional AI that delivers no business value, prototypes that cannot scale, and expensive experiments that erode stakeholder confidence in future AI investments.
The Data-to-Done framework addresses this directly. Each phase has defined inputs, outputs, decision gates, and success criteria. No phase is optional. Skipping a phase does not save time; it borrows time from the future at compound interest. Organisations that formalise MLOps and data governance reduce model time-to-production by 40%.
Phase 1: Business Problem Definition & Use Case Selection
Every successful AI project begins with a business problem, not a technology. Phase 1 translates a strategic challenge into a precisely scoped AI use case with measurable success criteria, a defined stakeholder, and a clear connection to revenue, cost, or risk.
The most common mistake in AI adoption is starting with the technology: “We need a machine learning model” or “We should use GPT for something.” Industry research consistently shows that starting with technology instead of business problems is a primary cause of AI failure. Phase 1 reverses this by demanding that the business problem comes first, and the technology selection waits until Phase 3.
Key activities: Stakeholder interviews to identify the highest-impact business problems. ROI estimation for each candidate use case. Feasibility assessment: does the required data exist, and is it accessible? Use case prioritisation using an impact-feasibility matrix. Definition of success metrics that the business — not the data team — will measure.
Phase output: A single, precisely scoped use case with a documented problem statement, success metric, executive sponsor, and estimated ROI. The use case must be narrow enough to deliver measurable results within 90 days, yet strategically significant enough to justify the investment.
Timeline: 1–2 weeks. Budget allocation: 5–10% of total project investment.
Decision gate: Proceed only if the use case has executive sponsorship, a quantifiable success metric, and confirmed data availability. If any element is missing, iterate — do not skip forward.
Phase 2: Data Audit & Readiness Assessment
Phase 2 is the most important phase in the entire framework — and the most frequently underestimated. Data readiness determines whether a custom AI project succeeds, and organisations that rush past this phase account for the majority of the 70–80% failure rate.
70% of AI failures originate from unresolved data issues. Informatica’s research identifies data quality as the top obstacle for 43% of organisations. Successful AI programmes invest 50–70% of their budget and timeline in data readiness — a ratio that shocks organisations expecting to spend most of their budget on the AI model itself.
Key activities: Comprehensive data inventory across all relevant systems. Data quality assessment: completeness (target >90%), accuracy, consistency, timeliness. Gap analysis: what data is missing, and how will gaps be addressed? Data accessibility audit: can the AI system access the data programmatically? Privacy and compliance review: GDPR implications, data residency requirements, consent status. Data governance baseline: who owns each data source, and what are the update frequencies?
The audit produces a Data Quality Scorecard that rates each data source on completeness, accuracy, consistency, and timeliness. Sources scoring below 70% require remediation before model development begins. This is not bureaucracy — it is risk management. A model trained on incomplete or inconsistent data will produce unreliable outputs regardless of how sophisticated the algorithm is.
Phase output: Data Quality Scorecard, gap remediation plan with timeline, data architecture diagram, privacy and compliance clearance.
Timeline: 2–4 weeks. Budget allocation: 20–30% of total project investment.
Decision gate: Proceed only when critical data sources score above 70% on the Data Quality Scorecard, or when a remediation plan with a defined timeline has been approved. If data readiness is fundamentally inadequate, restructure the use case around available data rather than forcing an unready dataset into production.
Phase 3: Solution Architecture & Technology Selection
Phase 3 designs the technical blueprint: which AI approach fits the use case, which infrastructure will support it, how the solution integrates with existing systems, and how it will scale from pilot to production without requiring a rebuild.
This phase answers the “build vs. buy vs. fine-tune” question with data, not assumptions. The architecture must account for current data volumes and projected growth, integration points with existing ERP, CRM, and operational systems, security and compliance requirements including EU AI Act obligations, latency requirements for real-time vs. batch processing, and the team’s ability to maintain and update the system post-deployment.
Key activities: Technology evaluation: cloud platform selection (Azure, AWS, GCP), AI/ML framework selection, integration middleware assessment. Architecture design: data pipelines, model serving infrastructure, monitoring dashboards, API design for system integration. Security architecture: data encryption, access controls, audit logging. Compliance architecture: transparency mechanisms, bias testing framework, human oversight protocols.
Phase output: Solution architecture document, technology stack specification, integration design, security and compliance framework, infrastructure cost estimate.
Timeline: 1–2 weeks. Budget allocation: 10–15% of total project investment.
Phase 4: Data Engineering & Model Development
Phase 4 transforms raw data into a trained AI model — but the emphasis is on engineering, not experimentation. The data pipeline that feeds the model is as important as the model itself, because a model without a reliable data pipeline is a prototype that cannot survive production.
This is the phase most people associate with “AI development,” but it typically represents only 20–30% of the total project effort. The preceding phases — problem definition, data audit, architecture design — ensure that the development effort is focused and efficient rather than exploratory and wasteful.
Key activities: Data pipeline construction: automated extraction, transformation, and loading (ETL) from source systems. Feature engineering: translating raw data into the variables the model needs. Model selection and training: choosing the appropriate AI approach (regression, classification, NLP, computer vision) based on the use case requirements. Model validation: testing accuracy, precision, recall, and bias against the success criteria defined in Phase 1. Documentation: model architecture, training data provenance, performance metrics — essential for EU AI Act compliance and ongoing maintenance.
According to a 2025 case study, a mid-sized financial services company allocated 22% of its custom AI budget to data preparation and 28% to algorithm development. This 50/50 split between data engineering and model development is typical of well-structured projects.
Phase output: Trained model meeting accuracy thresholds defined in Phase 1, automated data pipeline, model documentation, bias assessment report.
Timeline: 3–6 weeks. Budget allocation: 25–35% of total project investment.
Phase 5: Pilot Deployment & Validation
Phase 5 is the highest-risk transition in any AI project. This is where the pilot graveyard fills: 88% of AI pilots never reach production. The difference between the 12% that graduate and the 88% that stall is not model quality — it is deployment discipline.
The pilot operates in a controlled environment with real data, real users, and real business processes — but with defined boundaries. It is not a sandbox demonstration. It is a production rehearsal. The pilot must prove that the AI model performs accurately on live data, that users can interact with the system effectively, and that the business outcome defined in Phase 1 is achievable.
Key activities: Deploy the model in a controlled production-like environment. Run the pilot with a defined user group (typically 10–20% of end users). Measure performance against Phase 1 success criteria using live data. Collect user feedback on interface, workflow integration, and output quality. Identify edge cases, failure modes, and data drift patterns. Document pilot results with quantified metrics.
MIT’s research shows that mid-market firms can scale custom AI pilots in approximately 90 days when the scope is tightly defined. The 90-day timeframe is not arbitrary — it is long enough to validate accuracy on real data through seasonal and operational variations, but short enough to maintain stakeholder momentum and avoid the “permanent pilot” trap.
Phase output: Pilot results report with quantified metrics vs. success criteria, user feedback summary, edge case documentation, production readiness assessment, go/no-go recommendation.
Timeline: 3–4 weeks. Budget allocation: 10–15% of total project investment.
Decision gate: This is the critical gate. Proceed to production only if the pilot meets or exceeds the success criteria defined in Phase 1. If the pilot falls short, diagnose the root cause: is it data quality (return to Phase 2), model performance (iterate Phase 4), or workflow fit (redesign the integration)? Do not proceed to production with a “good enough” pilot — production will amplify every weakness.
Phase 6: Production Integration & Change Management
Phase 6 transitions the validated pilot into full production — and this is where the human dimension becomes as important as the technical dimension. A technically excellent AI system that users resist, distrust, or ignore delivers zero business value.
Production integration means embedding the AI outputs directly into the workflows where decisions are made. The AI does not operate in a separate dashboard or require a separate login. It appears inside the ERP, the CRM, the warehouse management system, or the financial reporting tool that users already use daily.
IMD’s 2025 AI Maturity Index concludes that “scaling AI is as much about managing change as it is about managing code.” Companies like Unilever, Visa, and Hitachi have trained tens of thousands of employees in AI fluency — a prerequisite for enterprise-wide deployment. For mid-market companies, the scale is smaller but the principle is identical: users must understand what the AI does, trust its outputs, and know when to override it.
Key activities: Full production deployment with monitoring. User training programme: what the AI does, how to interpret outputs, when to override. Communication plan: why the AI was deployed, what it means for each role, what it does not do. Feedback mechanism: structured channels for users to report issues, suggest improvements, and flag incorrect outputs. Performance monitoring: real-time dashboards tracking accuracy, latency, usage, and business impact metrics.
Phase output: Production-deployed system, trained user base, communication materials, feedback infrastructure, monitoring dashboards.
Timeline: 2–3 weeks. Budget allocation: 10–15% of total project investment.
Phase 7: Monitoring, Optimisation & Scaling
Phase 7 is not an endpoint — it is the beginning of continuous improvement. AI models degrade over time as data patterns shift, business processes evolve, and market conditions change. Without active monitoring and periodic retraining, even the best AI system becomes a liability.
Model drift — the gradual decline in accuracy as real-world data diverges from training data — is inevitable. A demand forecasting model trained on 2023–2024 data will lose accuracy as 2026 market conditions create patterns the model has never seen. Industry benchmarks show that annual AI maintenance typically runs 15–25% of the initial development cost. Organisations that allocate only 10% see performance decline within 14 months; those investing 20–25% maintain and improve accuracy continuously.
Key activities: Continuous performance monitoring: accuracy, precision, recall, and business impact metrics tracked in real-time. Data drift detection: automated alerts when input data distributions shift beyond defined thresholds. Scheduled retraining: periodic model updates using new data to maintain accuracy. Bias monitoring: ongoing testing for demographic or data-source biases that may emerge as usage scales. Scaling evaluation: identifying new use cases, new data sources, and expansion opportunities based on production performance data.
IDC research reports an average ROI of $3.70 for every dollar invested in AI, with top performers achieving returns of $10.30 per dollar. The difference between average and top-performing returns is largely attributable to Phase 7 discipline: top performers continuously optimise, retrain, and expand their AI systems, while average performers deploy and forget.
Phase output: Monitoring dashboards, retraining schedule, drift detection alerts, quarterly performance reports, scaling roadmap.
Timeline: Ongoing. Budget allocation: 15–25% of initial investment annually.
Timeline Overview: The 90-Day Pathway
For a tightly scoped mid-market AI project, the Data-to-Done framework delivers a validated, production-deployed AI system in approximately 90 days — significantly faster than the 18-month enterprise average that Gartner reports.
| Phase | Duration | Budget % | Key Output |
| 1. Business Problem Definition | 1–2 weeks | 5–10% | Scoped use case + success metric |
| 2. Data Audit & Readiness | 2–4 weeks | 20–30% | Data Quality Scorecard |
| 3. Solution Architecture | 1–2 weeks | 10–15% | Architecture document |
| 4. Data Engineering & Model | 3–6 weeks | 25–35% | Trained model + pipeline |
| 5. Pilot Deployment | 3–4 weeks | 10–15% | Pilot results + go/no-go |
| 6. Production & Change Mgmt | 2–3 weeks | 10–15% | Live system + trained users |
| 7. Monitoring & Optimisation | Ongoing | 15–25%/yr | Continuous improvement |
| TOTAL (Phases 1–6) | 12–21 weeks | 100% | Production AI system |
The 12–21 week range reflects the variability in data readiness. Organisations with clean, accessible data complete Phase 2 in two weeks and the entire framework in approximately 12 weeks. Organisations requiring significant data remediation spend four weeks in Phase 2 and longer in Phase 4, extending the total to 21 weeks. Either way, this is dramatically faster than the 18-month enterprise average — because the framework eliminates the wasted time caused by unclear problem definition, premature model development, and unplanned rework.
What Makes the Data-to-Done Approach Different
The Data-to-Done framework is not a theoretical model — it is an execution methodology designed for mid-market companies that cannot afford 18-month timelines, multi-million euro budgets, or the luxury of failure.
Three principles differentiate this framework from generic AI implementation guides:
Business-problem-first, not technology-first. Phase 1 forces the conversation to begin with revenue, cost, or risk — not with algorithms, platforms, or trends. This alignment ensures that every subsequent phase serves a defined business outcome. MIT’s research confirms that vendor-led implementations succeed 67% of the time versus 33% for internal builds — and the primary differentiator is this business-first discipline.
Data investment before model investment. Phase 2 receives the largest single budget allocation (20–30%) because data quality is the primary determinant of AI success. Organisations that skip or abbreviate the data audit pay for it in Phase 4 (model underperformance), Phase 5 (pilot failure), or Phase 7 (production drift). Investing upfront is cheaper than reworking later.
Decision gates, not hope gates. Each phase ends with a defined decision gate. Proceed, iterate, or stop. There is no “let’s proceed and hope it works out.” This disciplined approach prevents the two most expensive AI mistakes: deploying an underperforming model into production, and continuing to invest in a project that should have been stopped in Phase 2.
With Dutch subsidies through WBSO covering 30–40% of AI R&D costs, the effective investment for a mid-market Data-to-Done project ranges from €35,000 to €100,000 — with a typical payback period of 6–12 months based on the business outcome validated in Phase 5.
Veelgestelde Vragen
How long does a custom AI project take?
Using the Data-to-Done framework, a well-scoped mid-market project takes 12–21 weeks from problem definition to production deployment. MIT’s data confirms that mid-market firms scale custom AI pilots in approximately 90 days. The timeline depends primarily on data readiness: organisations with clean, accessible data deploy faster.
What are the phases of AI development?
The seven phases are: (1) Business Problem Definition, (2) Data Audit & Readiness, (3) Solution Architecture, (4) Data Engineering & Model Development, (5) Pilot Deployment & Validation, (6) Production Integration & Change Management, and (7) Monitoring, Optimisation & Scaling. Each phase has defined inputs, outputs, and decision gates.
Why does data readiness take so long?
50–70% of AI project timelines are consumed by data preparation because most organisations’ data is scattered across systems, formatted inconsistently, and incompletely documented. The data audit identifies these issues early, and the remediation plan addresses them before model development begins — preventing far more expensive rework later.
What happens if the pilot fails?
A pilot that does not meet success criteria is not a failure — it is a diagnostic signal. The decision gate at Phase 5 requires root cause analysis: is the problem data quality (return to Phase 2), model performance (iterate Phase 4), or workflow integration (redesign the deployment)? Disciplined iteration is cheaper than premature production deployment.
Do I need a data science team to follow this framework?
No. The framework is designed for implementation with a specialised external partner. MIT’s research shows vendor-led implementations succeed at twice the rate of internal builds. What you need internally is a technically literate project owner who can define the business problem, evaluate results, and manage the partnership.
How much does each phase cost?
For a mid-market project, total investment ranges from €50,000 to €200,000 depending on complexity. Phase 2 (data audit) and Phase 4 (model development) together account for 45–65% of the total budget. WBSO subsidies can reduce effective costs by 30–40%. Detailed cost breakdowns are covered in Section 7 of this series.
What is the expected ROI?
IDC research reports an average ROI of $3.70 for every dollar invested in AI, with top performers achieving $10.30 per dollar. The Data-to-Done framework targets the top-performer bracket by ensuring that every phase serves a defined business outcome with measurable success criteria.
Key Takeaways
- The Data-to-Done framework consists of seven phases: problem definition, data audit, architecture, development, pilot, production, and monitoring — each with defined decision gates.
- 50–70% of project timeline and 20–30% of budget should be allocated to data readiness — the single most important investment in any AI project.
- 88% of AI pilots never reach production; the Phase 5 decision gate is specifically designed to prevent premature production deployment.
- Mid-market firms using a structured methodology complete the full framework in 12–21 weeks — compared to the 18-month enterprise average.
- AI delivers an average $3.70 return per dollar invested, with top performers reaching $10.30 — the gap is determined by Phase 7 discipline (monitoring, retraining, optimisation).
Sources
1. MIT Project NANDA — The GenAI Divide: State of AI in Business 2025, July 2025. fortune.com
2. McKinsey & Company — Seizing the Agentic AI Advantage, June 2025. mckinsey.com
3. BCG — AI Adoption in 2024: 74% of Companies Struggle to Achieve and Scale Value, October 2024. bcg.com
4. Gartner — Predicts 30% of GenAI Projects Abandoned After POC by End of 2025, July 2024. gartner.com
5. S&P Global Market Intelligence — Voice of the Enterprise: AI & ML, Use Cases 2025. spglobal.com
6. WorkOS — Why Most Enterprise AI Projects Fail, July 2025. Cites McKinsey & Informatica CDO Insights 2025. workos.com
7. IDC / Microsoft — Generative AI ROI Report, January 2025. itpro.com
8. Naitive.cloud — Custom AI Models vs Off-the-Shelf: ROI Breakdown, July 2025. blog.naitive.cloud
9. IMD — 2025 AI Maturity Index: From Pilot to Implementation at Scale, November 2025. imd.org
10. RTS Labs — Enterprise AI Roadmap: The Complete 2026 Guide, December 2025. rtslabs.com
11. Workmate — Enterprise AI Roadmap: From Pilot to Production, October 2025. workmate.com
12. Promethium — CDO Guide: Enterprise AI Implementation Roadmap and Timeline, October 2025. promethium.ai
13. MultiQoS — AI Implementation Roadmap: From Pilot to Production in 90 Days, January 2026. multiqos.com
14. European Commission — Regulatory Framework for AI (EU AI Act). digital-strategy.ec.europa.eu
15. RVO — WBSO Subsidie. rvo.nl